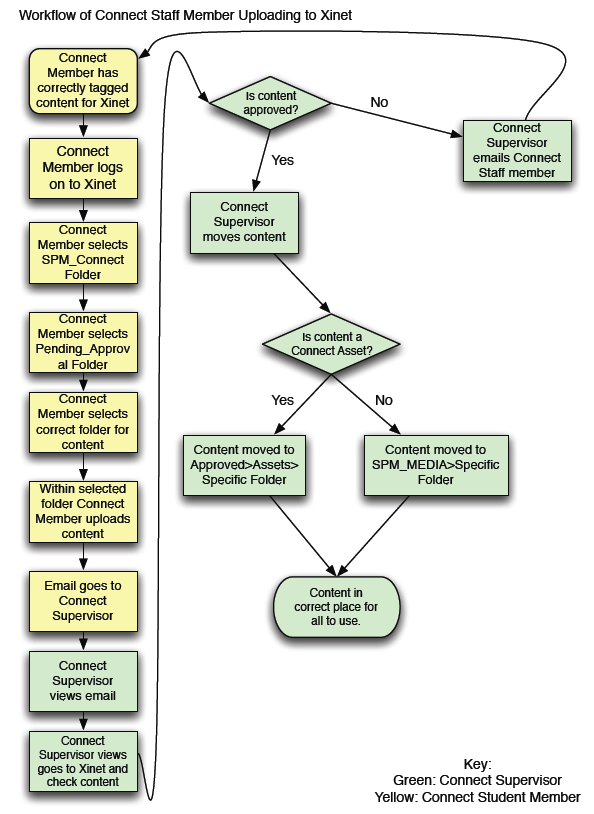
This is an overview of a proper workflow for students using a content management system, what do you think?
This is an overview of a proper workflow for students using a content management system, what do you think?
Working within a news organization there can be many files and often times metadata can become an issue when dealing with so many files. Recently, I have been working on learning to code within XML. It was through this new skill that I was able to code these trial custom metadata panels for use in Bridge. Theoretically our student news organization at RIT could use these panels to more accurately tag their files.

An example of the code used below:
<xmp_definitions xmlns:ui=”http://ns.adobe.com/xmp/fileinfo/ui/”>
<xmp_schema prefix=”spmetc” namespace=”http://spmetc.cias.rit.edu”
label=”$$$/AWS/FileInfoLib/Panels/spmetc/PanelName=spmetc”
description=”$$$/AWS/FileInfoLib/Panels/spmetc/PanelDescription=Custom metadata for spmetc”>
<!– simple properties –>
<!–This isn’t working correctly
<xmp_property name=”Status” category=”external” label=”$$$/Custom/Property/status_Label=Status:” type=”closedchoice” element_type=”text”>
<xmp_choice raw_value=”Unpublished” label=”$$$/Custom/Property/Choice_unpublished=unpublished”/>
<xmp_choice raw_value=”Published” label=”$$$/Custom/Property/Choice_published=Published”/>
</xmp_property>–>
<!–Use this–>
<xmp_property name=”event” category=”external” label=”$$$/Custom/Property/EventLabel=Event:”
type=”text”/>
<!– End of using this–>
<xmp_property name=”People” category=”external” type=”bag”
label=”$$$/Custom/Property/PeopleInput_Label=People:” element_type=”text” ui:multiLine=”true”
ui:height=”75″/>
</xmp_schema>
</xmp_definitions>
As the world becomes increasingly digitized, there is a new need for standardization of digital media files. The ways in which these files are stored are important, but even more so are the ways in which metadata is applied to allow one to search for a file once it has been placed within a content management system.
While looking at metadata standards, it is important to think about image capture standards as well. Images, especially those captured digitally, must meet certain criteria in order to be stored over a period of time, as well as allow for multiple uses. One example of image capture standards is the Digital Image Submission Criteria (DISC) standards provided by the IDEAlliance. DISC gives advice on how to store images for maximum reproduction in print and other media, while also lending itself to proper archival storage of digital images and files.
The DISC standards allow for digital media creators and publishers to deal with common problems found within a digital workflow. By following image standards, the digital file creator is able to determine the minimum quality level for digital images for printed output. Such standards also provide a way of creating a contract between the creator of the file and the acceptor, by creating guidelines specifying how images will be accepted or rejected. The DISC surveys also determine what format images should be submitted in. For example, in our Xinet project it was determined that images would be submitted as tiff files, using LAB color space and be at least 8 bit depth. A final aspect is how images should be labeled so that they fit within the digital workflow. This allows the image takers to create a standard to reach towards when outputting their work to the collective (Dougherty 2).
When images are rejected, it is understood that it is because the files did not meet the requirements laid out by the image standards. It is common for photographers and other digital file creators to not even receive payment for their work in the digital workflow world if their files do not follow the standards set forth by the receiving digital workflow. In a way, standards for image capture serves as a contract for both parties involved in the digital workflow.
Metadata is often utilized within the DISC standards. One aspect of metadata is the use of keywords to allow files to be searched. An important part of this includes the use of keywords. Keywords are part of an access structure, which “relates content types or publication pages to each other or to an external set of concepts that can be used to get to a particular content type” (Boiko par 40). Keywords fall within the indexing structure of metadata in the ranking of access structures making it the one of the most important fields. Keyword entry may come in different forms, for example in the IPTC Core, in which there is a spot for keywords. Similarly, within some museum systems there is a “Subject Matter—Description…A description of the work in terms of the generic elements of the image or images depicted in, on, or by it,” which may also hold keywords (Harpring par 10).
It is important when using keywords that taxonomy is applied to them. Since keywords may be free text, it is important to have a standard when using them (Dougherty 6). Taxonomy allows for “an orderly classification that explicitly expresses the relationships, usually hierarchical (e.g., genus/species, whole/part, class/instance), between and among the things being classified” (Gill par 80). It is also important to keep in mind that many times keywords are known as open lists so you must “make sure that you trust users to add new items responsibly” (Boiko 10). When creating keywords, you must keep in mind the result – an extensible series of categories for organizing digital assets into meaningful sets (Bock 4).
 “Using a taxonomy, we know how to relate one term in the information hierarchy to another” (Bock 5). If we look at this from the perspective of a cataloger of an art museum, it may take place in three steps. The first is where keywords entered may be generic, such as “nude” or “woman”, which are elements that would be easily observable to any person that is viewing the work. The next level would be identification, providing information that is generally more specific, such as “Birth of Venus.” Finally, the last set of keywords would deal with an even more specific set of terms that allow for interpretation, for example “Sandro Botticelli Classiest representation of Venus Birth” (Harpring par 20).
“Using a taxonomy, we know how to relate one term in the information hierarchy to another” (Bock 5). If we look at this from the perspective of a cataloger of an art museum, it may take place in three steps. The first is where keywords entered may be generic, such as “nude” or “woman”, which are elements that would be easily observable to any person that is viewing the work. The next level would be identification, providing information that is generally more specific, such as “Birth of Venus.” Finally, the last set of keywords would deal with an even more specific set of terms that allow for interpretation, for example “Sandro Botticelli Classiest representation of Venus Birth” (Harpring par 20).
In respect to my experience with Xinet for a classproject, the keywords were chosen in a similar fashion to the hierarchy described in Introduction to Art Image Access, Issues, Tools, Standards, and Strategies. The first level of keywords for the images represents an overall knowledge of the subject matter. For example, the topic chosen for the images was baked goods, so the first keyword to be entered was “food” since this is a general term for anything editable (and the baked goods are food). Next, a keyword identifying the type of food was added – bakery. Since the baked goods came from a specific store, it was also added so that someone searching for the bakery name would be able to find it, along with “menu” to denote that this may be found year round in their store. In addition, “sweets” was added to show the type of baked good in the photo. Finally, the specific name of the baked good was added, “vanilla bean slice”.
It is important to use taxonomy within any type of database when dealing with digital media, as it allows users of all occupations and knowledge bases to easily search for images in a timely manner while preserving the original intent of the digital media.
References:
Bock, G. E. (2005, October). Designing Metadata An Implementers Guide for Organizing and Using Digital Assets. Bock and Company, 1, 21.
Boiko, Bob. (2005). Content management bible, 2nd edition.
[Books24x7 version] Available from.
Dougherty, J., & Lam, K. w. (2007, May). DISC 2007 Specifications and Guidelines. Graphic Arts Monthly, 1, 9.
Gill, T., Gilliland, A. J., Whalen, M., & Woodley, M. S. (n.d.). Introduction to Metadata (Research at the Getty). The Getty. Retrieved January 1, 2011, from web.
Layne, S. S., Harpring, P., Hourihane, C., & Sundt, C. L. (n.d.). Introduction to Art Image Access (Research at the Getty). The Getty. Retrieved January 1, 2011, from web.
Recently I had a chance to take a class on XML and print publishing workflow. When I looked around the room on the day of our first lab, all I saw was straight fear of the XML authoring environment. I found that more people had trouble with the interaction of the authoring environment than was expected which leaves me to wonder about is out there in terms of XML authoring.
Ways to Improve on XML Authoring
In order to solve such issues, of non XML centric users interacting with authoring enviroments, several of the bigger names in software have created semi-solutions to the interface problem. The first of these companies is Woodwing Software. A company based in the Netherlands, Woodwing utilizes plug-ins for designers to work within XML. Wooding’s solution is Smart Catalog, a solution for publishing structured data within InDesign.
Smart Catalog allows for three panels within InDesign. The first is Smart Catalog panel that shows any records associated with the content. The second is a Formatting Rules panel that allow for XML elements to appear as “rules” for the content. Lastly is a Smart Catalog Fields panel, which allows for the individual fields to be edited once they are placed in the document. It is through these three panels that the designer can edit content in a environment with which they are familiar, without actually seeing the XML code (Woodwing 2011).
Adobe also has a solution for XML publishing that is called the Adobe Digital Publishing Suite. Currently, Condé Nast, Martha Stewart, Reader’s Digest and many more use the Adobe Digital Publishing Suite. This software is used mainly for e-reader and tablet publishing and allows for XML components to be integrated into InDesign through the use of overlays. The files are saved in a proprietary format of “.folio”, which is said to be cross platform allowing for exportation across multiple formats. Adobe also has a product called Adobe Digital Editions that allows for the organization “to view and manage eBooks and other digital publications” (Adobe 2011).
Finally, the most interesting solution may lie with the publishing software vendor Quark. Quark XML Author is created for integration with Microsoft Word. Within the Quark XML Authoring program, “authors can create information components that feed directly into the Quark Publishing System, which can automatically combine these components, create high-quality print pages, and generate digital versions for the Web and other formats”. This method requires no knowledge of XML from the author and gives no indication to the author they are using an XML backed product. It is an ideal solution to adoption, as it allows the content author to use the tool s/he is already familiar with, requiring no extra steps of XML implementation.
The Quark software also utilizes DITA for its flexibility for “map creation and editing” and emphasizes that, with the use of Word in the front end, DITA mapping is more intuitive (Quark 2011). “DITA can be modeled for both static and dynamic publishing” which is most likely why Quark has chosen to go with this method of authoring. Using DITA with Word helps to enforce the idea to the content creator that “it’s not about the tools; it’s about the process” (Day 2010).
Ways to Improve on XML Authoring
While the solutions offered by Adobe and Woodwing are definitely an important step in the right direction, they seem as though they are not complete. For an authoring environment to be truly successful, there needs to be a next step. We need a better solution than add-ons. Even though DocBook and DITA are a step in the right direction, they are not intuitive without some programming background to begin with, or some sort of training. Developers need to take a step back when creating authoring environments and begin to think of the everyday worker.
Solutions for this problem maybe closer than one would think. In an ideal world, there would a software program that combines both the editing capabilities of Oxygen (sorry to purposely misuse capitals when writing this name but it spelled so strangley) and the design ability of InDesign. This program would allow for the XML to be visible if the user wishes, but allow for design templates to automatically format themselves to the XML hierarchy as necessary. Instead of saving a single file within this program, the content would be packaged and allow for the XML to be stored with the output design. It would allow for the user to choose multiple output formats and adjust the content accordingly. This program would not be impossible to make, but it is asking a lot for people to rethink and abandon the programs they use everyday.
A clearer, and potentially much easier, solution would be for companies such as Adobe, Quark and Microsoft to rethink the way their current authoring programs work. For example, InDesign does have an XML feature. However, it is clearly not user friendly, nor is it robust enough to be effective in the long-term world of cross media publishing and XML authoring. Microsoft may also have to look at the way in which they allow access to XML within their files. Currently, it is an arduous task to extract XML from Word Documents, and writers like Word, so moving them is not an option. Microsoft could easily adjust the back end of Word to allow for XML hierarchies to be more easily accessible through files.
In the case of current programs such as InDesign and Microsoft Word, the author has the freedom to create documents in whatever order they choose. Should XML authoring in these programs continue to develop, creative jobs may not appreciate the idea that they must be forced to think within a hierarchy. This may be the reason that the current processes of XML and creative work is separated. However, as we put more demands on publishers to use XML backed software and applications, it will eventually feed into the jobs of writers and designers – they will eventually have XML as a skill set. However, just like photography’s change from digital to film, there needs to be a change in the way processes are thought of, and this may take a while to occur. When this change happens, the vendors of the software creative workers need have to ensure that they allow for an ease of transition.
Conclusion
Before a mass standardization of authoring environments occurs, there must be an overall acceptance from the content creators (I recognize it is a two way street, even though we were all scared as designers to touch XML that first time, you kinda have to) that XML and the cross media workflow is here to stay. When looking at the content community today, we are beginning to see this happening. However, hindering the development of XML are the companies who create the authoring environments. These companies are correct in developing the tools for the content creator within programs they are already familiar, but the current add-ons only add to the frustration of understanding for the content creator, as they are not user friendly. It is not until XML is truly integrated into the interfaces of common programs that the content creator and development companies will see a push forward in XML authoring.
In the future, there will hopefully be a content creator that has a full understanding of XML along with companies that answer this need with XML authoring environments that allow for a streamlined creative process.
References
Adobe. (2011). Adobe Content Authoring Solutions.
Beaudoux, O., Blouin, A., &, J.-M. (n.d.). Using Model Driven Engineering Technologies for Building Authoring Applications.
Boiko, B. (2002). Content management bible.
Brun, C., Dymetman, M., & Lux, V. (2000, July). Document Structure and Multilingual Authoring. COLING ‘00: Proceedings of the 18th conference on Computational linguistics – Volume 1.
Cagle, K. (2008, May 21). Dita, DocBook and the Art of the Document [Web log post]. Retrieved from http://www.oreillynet.com/xml/blog/2008/05/dita_docbook_and_the_art_of_th.html
Dawson, L. (Speaker). (2011, February 18). Webcast Video: Essential Tools of an XML Workflow – O’Reilly Radar [Audio podcast].
Day, D. (2010, October). Everyday DITA; connecting content beyond tech pubs. PowerPoint presented at XML 2010 eMedia Revolution, A Conference of IDEAlliance, Philadelphia, PA.
DITA XML.org [The official community gathering place and information resource for the DITA OASIS Standard]. (2011).
DocBook. (n.d.). What is DocBook?
Healy, M. (2009). An Introduction to StartWithXML. PowerPoint presented at Presentations from the StartWithXML Forum.
Jacob, I. E., & Dekhtyar, A. (2005, June). xTagger: a New Approach to Authoring Document-centric XML. JCDL ‘05: Proceedings of the 5th ACM/IEEE-CS joint conference on Digital libraries.
Koong, C.-S., Lee, C.-M., Chen, D.-J., Chang, C.-H., & Shih, C. (2009). The Visual Authoring Tool of Flash-based Component for Interactive Item Template.
Meredith Corporation. (2010). Meredith Corporation and XML. Powerpoint presented at XML 2010 eMedia Revolution, A Confrence of IDEAlliance, Philadelphia, PA.
O’Keefe, S. (2009). Structured authoring and XML (Monograph). North Carolina, USA: Scriptorium Publishing Services, Inc.
Quark. (2011). XML Authoring.
Quint, V. (2004). Techniques for Authoring Complex XML Documents. DocEng ‘04: Proceedings of the 2004 ACM symposium on Document engineering.
Stewart, J. (2010). Structured content creation and the future of Cross-Media publishing of c. Powerpoint presented at XML 2010 eMedia Revolution, A Conference of IDEAlliance, Philidelphia, PA.
Téllez, A. G. (n.d.). Authoring Environment for E-learning Production Based on Independent XML Formats.
Walsh, N., & MarkLogic Corporation (Speakers). (2010). What’s new in DocBook V5?
Woodwing. (2011). Woodwing [Cross Media Publishing].
Young, D. (2009). XML–Why Bother? PowerPoint presented at Presentations from the StartWithXML Forum.
